기존의 인공신경망은 순차적인 정보가 담긴 데이터를 처리하는 것에 어려움이 있습니다.
1. RNN(Recurrent Neural Network)
(1) RNN이란?
시간 순서대로 들어오는 Seuqence data를 모델링하기 위한 Network입니다. 다른 Neural Network와는 달리, 지금까지 입력된 데이터를 요약한 hidden state를 가지고 있습니다. 입력이 들어올 때마다 hidden state를 수정하는 식으로 동작하므로, 입력을 모두 처리하고 난 네트워크의 hidden state는 sequence 전체를 요약하는 정보가 됩니다.
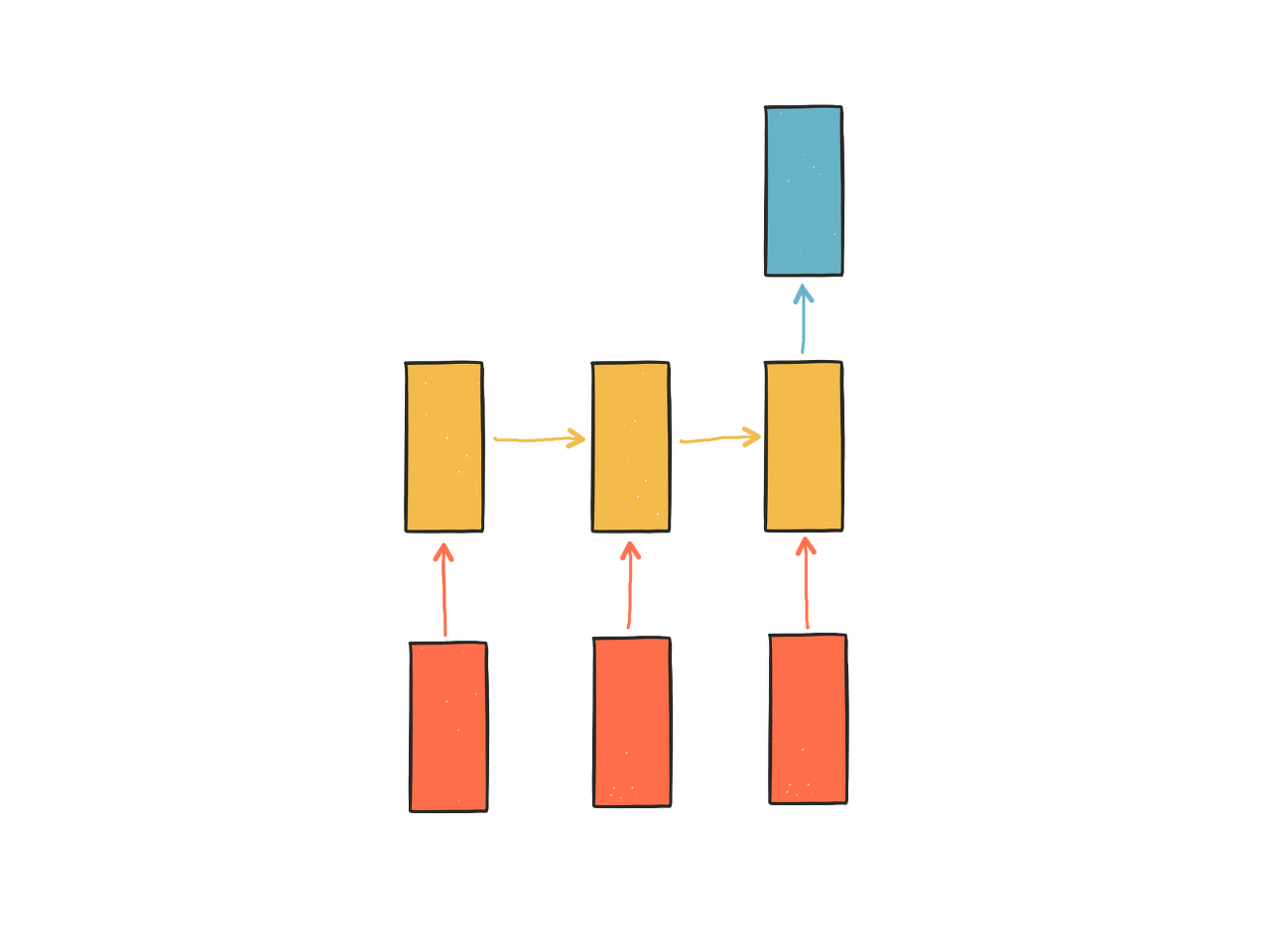
빨간색 노드 : 입력
노란색 노드 : hidden state(기억)
파란색 노드 : 출력
- 첫번째 입력이 들어오면 첫번째 hidden state가 만들어짐
- 두번째 입력이 들어오면 첫번째 hidden state를 참고하여 두번째 hidden state가 만들어짐
RNN 모델은 순차적인 정보가 담긴 데이터, 즉 Sequence Data를 잘 처리할 수 있습니다.. 이전 상태의 hidden layer의 결과가, 다음 순서의 hidden layer의 입력으로 들어갑니다. 이전 상태를 보존하면서 새로운 상태를 받아들이기 때문에, 입력값의 시간 순서를 기억한다고 볼 수 있습니다. 즉, 순차적인 데이터 입력에 따라 문맥 정보 파악이 가능합니다.
RNN은 입력 값 크기 제한이 존재하지 않지만, 장기 의존성 문제가 있습니다. 장기 의존성 문제란, 긴 sequence가 들어오면, 처음 입력한 데이터를 모델이 잊어버려서 효과적으로 처리할 수 없는 문제입니다.
RNN 모델은, 아래와 같이 시간 흐름에 따라 Unfold하여 바라볼 수 있습니다.

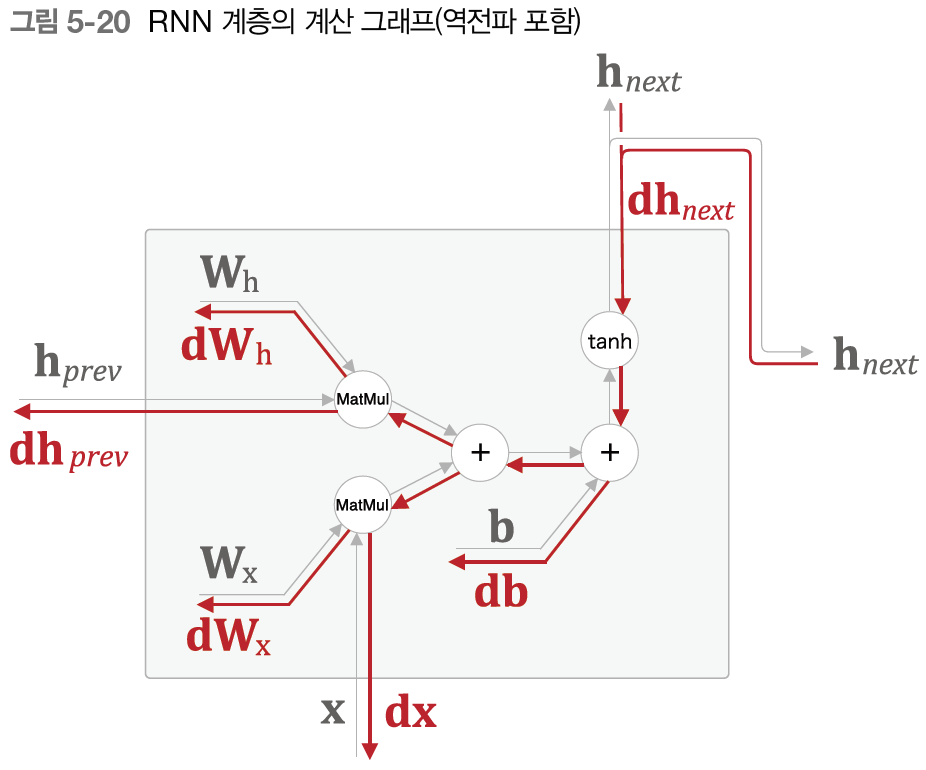
$h_t = tanh( h_{t-1} W_h + x_t W_x + b)$
$W_x$ : 입력 $x$를 출력 $h$로 변환하기 위한 가중치
$W_h$ : 하나의 RNN 출력을 다음 시각의 출력으로 변환하기 위한 가중치
$b$ : 편향
$h_t$ : 시각 $t$의 출력. hidden state(은닉 상태), hidden state vector(은닉 상태 벡터)라고 부른다.
현재의 출력 $h_t$는 한 시각 이전의 출력 $h_{t-1}$에 기초해 계산됩니다. 이전 시점의 상태를 가지고 있으므로, RNN 모델은 상태를 가지는 계층, 즉 메모리가 있는 layer라고 합니다.
Time Softmax with Loss 계층
T개의 Affine 계층을 묶어서 Time Affine 계층을 만들 수 있습니다. loss 함수는, 각각의 Affine 계층에 해당되는 Loss를 평균낸 값과 같습니다.
$L = {1 \over T} (L_0 + L_1 + ... + L_{T-1}) $
(2) Backpropagation Through Time (BPTT)
BPTT는 시간 방향으로 펼친 신경망의 오차 역전파법입니다. RNN에서 사용하는 오차역전파법입니다. RNN에선 현재 step과 이전 step이 연결되어 있기 때문에 시간을 거슬러 올라가며 backpropagation을 진행합니다. 역전파의 연결은 끊어지지만 순전파의 연결은 끊어지지 않습니다.
a. 사용되는 함수
- Softmax: 값의 분포에 따른 출현 확률
- Cross-Entropy: 두 개의 확률 분포의 비슷한 정도를 나타내는 지표, 0에 가까울 수록 확률 분포가 비슷하다
softmax를 통해 나오는 예측값이 확률 분포이므로, 오차함수는 Cross-Entropy를 사용합니다.
b. Vanishing gradient
backpropagation through time에서, step의 길이가 길어질수록 편도함수 값이 0에 수렴하는 문제입니다.
b-1. Truncated BPTT (단기 BPTT)
시간 축 방향으로 매우 길어진 신경망을 적당한 지점에서 잘라내어 작은 신경망 여러 개로 만든 뒤 학습하는 방법입니다. 역전파의 연결을 끊었다고 해서 순전파의 연결이 끊어지는 것은 아닙니다. 즉, 데이터는 순서대로 입력해야 합니다.
모든 시간에 대한 hidden layer의 값을 저장하는 것은 현실적으로 불가능합니다. 또한, Sequence Data의 길이가 너무 길어지만, bacopropagation시 gradiant가 0으로 수렴되어 학습이 진행되지 못할 수 있습니다. 이 문제를 해결하기 위해 Truncated BPTT를 사용합니다.
b-2. 해결 방법
- LSTM, GRU : RNN의 구조를 변형하여 문제 해결 (link)
- Bidirectional Recurrent Neural Networks (BRNNs): 데이터를 RNN 모델에 넣을 때 정방향/역방향의 두 방향으로 넣는다.
(3) RNN의 예시
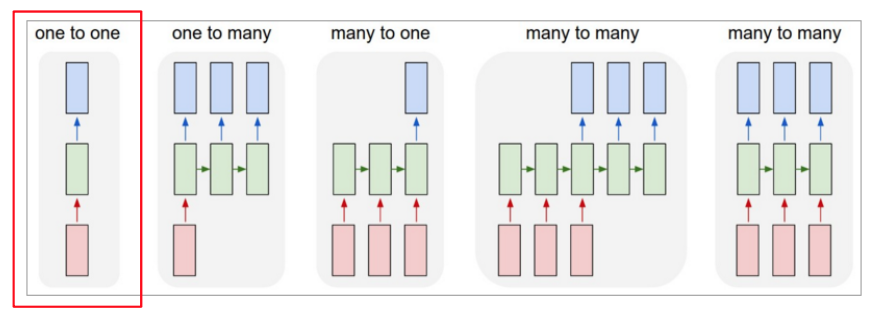
a. one to one
- 고정 input, 고정 output
- perceptron. 신경망의 기본적인 구조
- 순환적인 부분이 없기 때문에 RNN이 아님.
b. one to many
- 고정 input, 시퀀스 output
- image captioning : 이미지를 가지고 Sequence of words 생산
- 이미지 -> 들판 위에 구름이 낀 하늘이 있다.
c. many to one
- 시퀀스 input, 고정 output
- Sentiment analysis
- sequence of words -> sentiment\
- 주어진 문장의 감정 상태를 분석한다 (afinn, vader)
d. many to many
- 시퀀스 input, 시퀀스 output
- Machine Translation
- sequence of words -> sequence of words
- 번역기 : encoder to decoder라고도 한다
e. many to many
- 동기화된 시퀀스 input, 시퀀스 output
- Search term autocomplete
- sequence of words -> sequence o words
- 자동 완성 검색어
RNN은 입력된지 시간이 오래 지난 데이터는 잘 보존하지 못하는 문제가 있습니다. 이 문제를 해결한 네트워크로는 LSTM이나 GRU 등이 있습니다.
(4) RNN의 평가
a. perplexity(혼란도)
- 데이터 수가 하나일 떄, 확률의 역수입니다.
- 이 값이 1에 가까울수록 예측이 확실하게 되었다고 볼 수 있습니다.
- 좋은 모델은 정답을 높은 확률로 예측하므로 perplexity 값이 적습니다. 나쁜 모델은 정답을 낮은 확률로 예측하므로 perplexity 값이 높습니다.
2. Reference
- RNN과 LSTM을 이해해보자!
- BRNN : 이후의 정보도 기억하는 BRNN
- RNN 이해하기
- 수학적 관점으로 보는 BPTT
'Model > Layer' 카테고리의 다른 글
| CNN 모델 (0) | 2020.04.12 |
|---|---|
| CNN만들기 (0) | 2020.04.12 |
| CNN(Convolution Neural Network)이란? (0) | 2020.04.12 |
| DNN (Deep Neural Network, 심층 신경망) (0) | 2020.04.12 |
| Layer (0) | 2020.04.12 |

