GAN(Generative Adversarial Network)은 두 개의 신경망 모델이 서로 경쟁하면서 더 나은 결과를 만들어내는 강화 학습의 일종입니다.
GAN은 Generator(생성자)와 Discriminator(감별자)로 구성되어 있습니다. Generator는 거짓 데이터를 만들어내는 모델입니다. 생성된 데이터는 Discriminator가 실제 데이터로 착각하도록 학습을 합니다. 한편, Discriminator는 실제 데이터와 Generator가 생성한 거짓 데이터를 구분하는 모델입니다.
두 모델이 서로 경쟁을 하다보면, Generator는 진짜 같은 데이터를 생성하게 되고, Discriminator는 실제 데이터와 거짓 데이터를 더더욱 잘 구분할 수 있게 학습이 됩니다.
1. Adversarial Nets

Adversarial Net은 Generator와 Discriminator가 서로 경쟁하면서, Generator는 가짜 이미지를 더 잘 생성해 내게 되고, Discriminator는 가짜 이미지를 더 잘 판별할 수 있도록 학습됩니다.
- Discriminator는 Training set에 있는 실제 이미지는 real(1)로, Generator가 만든 가짜 이미지는 Fake(0)으로 판단하도록 학습합니다.
- Generator는 Generator가 생성한 이미지가 real(1)로 판별되도록 학습합니다. (Discriminator는 freeze된 상태)
아래 예제를 통해 GAN이 학습하는 방법을 살펴봅시다.

위 이미지의 검정색 점은, data generating distribution으로, 미리 주어진 real 데이터로 볼 수 있습니다. 녹색 실선은 generative distribution $p_g(G)$인데 Generator가 생성한 데이터입니다. 파란색 점선은 Discriminator의 확률 분포입니다. 실제 데이터일 확률이 높으면 1, 가짜 데이터일 확률이 높으면 0에 가까워집니다. z에서 x로 가는 화살표는 random 노이즈 z에서 생성된 데이터값을 의미합니다.
(a) Discriminator가 Generator가 생성한 데이터가 real/fake인지 어느 대략적으로만 하고 있는 상황입니다.
(b) Discriminator를 학습해서 데이터의 real/fake 여부를 더 잘 판단할 수 있게 되었습니다.
$D^*(x) = p_{data}(x) / (p_{data}(x) + p_g(x))$
(c) Generator를 더 학습했더니 보다 real data에 가까운 데이터를 생성할 수 있게 되었습니다.
(d) b, c 과정을 계속 거치면서 학습을 충분히 진행하다보면, 모델을 더 이상 향상시킬 수 없는 상태가 됩니다. 모델이 생성한 확률분포 $p_g$가 실제 데이터의 분포인 $p_data$와 동일해졌기 때문입니다. Discriminator는 더 이상 real/fake 구분을 할 수 없게 되어서, $D(x) = 1/2$가 됩니다.
이 내용을 수식으로 나타내면 아래와 같습니다.
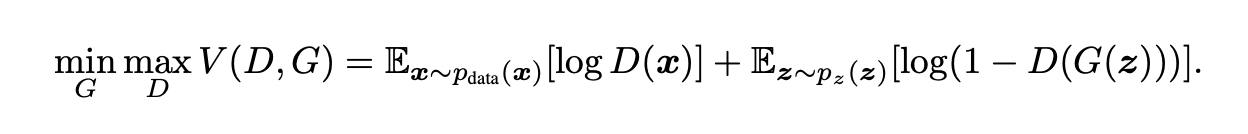
위 수식은 minmax cost function입니다. G를 학습할 땐 위 수식의 값이 감소하고, D를 학습할 땐 위 수식의 값이 증가하도록 학습합니다.
G가 잘 학습되면 $D(G(z))$ 값이 1(real data)가 되기 때문에 $log(1-D(G(z))$ 값이 0이 되므로 위 cost 함수의 값이 감소합니다. D가 잘 학습되면 $D(G(z))$ 값이 0이 되기 때문에 $log(1-D(G(z))$ 값이 1이 되어 위 cost 함수의 값이 증가합니다.
이 과정을 풀어서 다시 설명하면 아래와 같습니다.
(1) Discriminator 학습
- $p_g(z)$에서 m개의 noise sample ${z^{(1)}, ..., z^{(m)}$을 샘플링합니다.
- $p_{data}(x)$에서 m개의 example ${x^{(1)}, ..., x^{(m)}$을 샘플링합니다.
- 아래 stochastic gradiant 값이 증가하도록 discriminator를 학습합니다. 그리고 이 과정을 k step만큼 반복합니다.
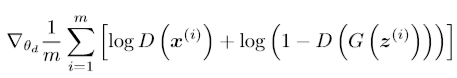
(2) Generator 학습
- $p_g(z)$에서 m개의 noise sample ${z^{(1)}, ..., z^{(m)}$을 샘플링합니다.
- 아래의 stochastic gradiant 값이 감소하도록 Generator를 학습합니다.
위 두 단계가 하나의 epoch입니다. 이 과정을 training iteration만큼 반복합니다.
2. Example
MNIST 데이터셋을 이용해 GAN을 학습시켰을 때, epoch가 커질수록 더욱 정교한 이미지가 생성되는 것을 확인할 수 있습니다. epoch 1일 때 Generator가 생성한 숫자 이미지는 아래와 같습니다.

epoch가 30정도 되면 숫자의 형태가 희미하게 나타나기 시작하며,

ecoch가 100이 되면 글자의 형태는 보이기 시작합니다.

epoch가 300 정도 되면 아래와 같이 숫자가 생성되는 것을 볼 수 있습니다.

모델의 구조나 하이퍼파라미터에 따라서 학습 속도나 생성되는 이미지의 품질은 다를 수 있습니다.
3. Reference
- [IT열쇳말] GAN(생성적 적대 신경망)
- 쉽게 쓰여진 GAN: GAN 개념 + MNIST (Pytorch)
- Generative Adversarial Networks (GANs) 이해하기: GAN 개념 + MNIST에 적용하는 예제 (keras)
- [번역] Keras를 사용한 GAN 예제
- Github: Zackory/Keras-MNIST-GAN: GAN을 MNIST에 keras로 적용한 예제
- 1시간만에 GAN(Generative Adversarial Network) 완전 정복하기 (요약)
- 초짜 대학원생 입장에서 이해하는 Generative Adversarial Nets - #1, #2
'Model > Network' 카테고리의 다른 글
| Autoencoder (0) | 2020.04.12 |
|---|---|
| Transformer (0) | 2020.04.12 |
| Attention Network, Attention Model (0) | 2020.04.12 |
| Autoencoder / VAE (0) | 2020.04.12 |


