본 포스트는 Attention Network, Attention Model의 정의, 구조, 및 활용에 대해 설명합니다. Natural Language Inference, Sentence representation and Attention Mechanism 논문을 요약 및 정리하고 추가적인 내용을 덧붙였습니다.
Attention Model이란 딥러닝 모델이 vector sequence 중에서 가장 중요한 vector에 집중하도록 하는 모델입니다. State를 고려해서 가장 중요도가 높은 vector를 중심으로 하나의 vector로 정리하는 모델입니다.
Attention Model의 input은 입력 벡터와 context가 있습니다.
- 입력 벡터($y_1, y_2, ..., y_n$): 1차원 데이터 뿐만 아니라 2차원 데이터(이미지 등)도 가능
- Content ($c$): 문맥 등 현재 상태를 나타내는 벡터.
Attention Model의 output $z$는, content와 sequence를 고려하여 $y$ 벡터 중 가장 중요한 벡터 위주로 summary한 값입니다. 즉, Sequence의 중요한 부분에 집중한다고 볼 수 있습니다.
1. Attention Model의 구조와 동작 방법

Attention Model은 개념적으로 아래와 같이 동작합니다.
- Input으로 들어온 벡터들의 중요도/유사도를, 현재 state를 고려하여 구합니다.
- 각각의 중요도를, 총 합이 1이 되는 상대값으로 바꿉니다.
- 상대값 중요도를 가중치로 보고, Sequence에 있는 벡터들을 가중치합을 합니다.
Attention Model을 구현하는 방법은 여러 가지가 있으나, 그 중에서 tanh 함수와 내적곱을 이용한 Attention은 아래와 같이 구현할 수 있습니다.

- State $C$에 $W_c$ 행렬를 내적한 값과, 각각의 Sequence의 벡터 $y_i$에 $W_y$ 행렬를 내적한 값을 더합니다. 그리고 이 값을 tanh 함수에 통과킨 값을 $m_i$이라고 합니다.
- $m_i$ 값을 Softmax 함수에 통과시켜 확률을 구한 값을 $s_i$라고 합니다.
- $s_i$ 값과 $y_i$ 값을 내적한다. 이 값을 전부 합친 것이 출력값이 됩니다.
여기서 $W_c, W_y$ 행렬은 학습을 통해 값을 정합니다. 1에서 사용한 방법은 $y_i$ 값과 $C$ 값을 하나로 섞는 이상 어떤 방법을 사용해도 무방합니다.
- 여기서 W_c, W_y 행렬은 학습을 통해 값을 정한다.
- 1에서 사용한 방법은 y_i 값과 C 값을 하나로 섞는 이상, 어떠한 방법을 사용해도 무방하다. (예: y_i와 C 값을 내적)
RNN을 사용하는 경우 이전 RNN layer의 출력값이 모두 나와야 Attention Model의 출력을 정할 수 있습니다. Attention Model은 이전 layer의 출력값 전체를 Input으로 받기 때문입니다.
2. Encoder/Decoder와 Attention Machanism
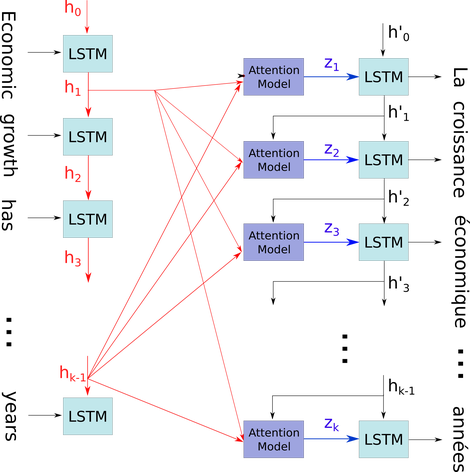
encoder(인코더), decoder(디코더) 구조로 되어 있는 번역 모델이 있다고 해 봅시다. 일반적인 모델은 인코더의 모든 출력 벡터를 보고 decoder의 값을 출력합니다. 하지만, Attention Mechanism은 인코더의 출력 벡터 중에서 중요한 벡터에 집중합니다. 에를 들어 "Artificial Intelligence"를 "인공 지능"으로 번역할 때, '지능'을 출력하는 경우 'intelligence' 값에 집중한다고 볼 수 있습니다. 이와 같이 Decoding 과정에서 불필요한 벡터를 보지 않으므로 성능이 향상됩니다.
RNN Encoder/Decoder를 사용할 때 Attention Model의 Input은 아래와 같습니다.
- $y_1, y_2, ..., y_n$: 보통 이전 RNN layer가 출력한 값의 Sequence로 사용합니다.
- $c$: Attention Model의 Output을 사용하는 RNN 모델의 바로 직전 State를 사용할 수 있습니다. 예를 들어 RNN 모델의 세 번째 Output을 계산한다면, 두 번째 Output의 hidden state 값을 사용할 수 있습니다.
3. Attention Model의 Code Example
3-1. 이전 layer의 출력 값이 1차원인 경우
# 이전 layer의 전체 값들을 Input으로 받는다
inputs = Input(shape=(input_dims,))
# 각각의 값에 대한 중요도를 구한다.
attention_probs = Dense(input_dims, activation='softmax', name='attention_probs')(inputs)
# 각각의 값 Matrix와 중요도 Matrix를 행렬곱한다. 즉, 입력 값들을 중요도에 따라 가중치합한다.
attention_mul = merge([inputs, attention_probs], output_shape=input_dims, name='attention_mul', mode='mul')-
philipperemy/keras-attention-mechanism에서 소스를 가져와 주석을 달음.
수학적인 의미의 행렬(Matrix)를 Dense Layer로 대체하여 구현하였습니다.
3-2. 이전 layer의 출력이 2차원인 경우
# inputs.shape = (batch_size, time_steps, input_dim)
input_dim = int(inputs.shape[2])
# Input Matrix를 Transpose한다.
a = Permute((2, 1))(inputs)
a = Reshape((input_dim, TIME_STEPS))(a)
# 각각의 값에 따라 중요도를 구한다. (LSTM의 cell 별)
# Matrix로 보면, 아래 layer의 출력은 행: sequence index, 열: input_dim
a = Dense(TIME_STEPS, activation='softmax')(a)
# 다시 Matrix를 Transpose해서 Input Matrix와 차원의 의미가 같도록 수정
a_probs = Permute((2, 1), name='attention_vec')(a)
# a_probs - 행: input_dim, 열: sequence index
# Input 값들을 중요도에 따라 가중치합한다.
output_attention_mul = merge([inputs, a_probs], name='attention_mul', mode='mul')-
philipperemy/keras-attention-mechanism에서 소스를 가져와 주석을 달음.
"각각의 Sequence의 벡터 $y_i$에 $W_y$ Matrix를 내적한 값을 더한다."를 Dense layer로 구현하기 위해 Input Matrix를 Transpose합니다. Attention은 하나의 dimension에 대해, 여러 time_step sequence에 대해서 중요도를 구합니다. 위 코드는 input의 차원 순서가 (batch_size, time_steps, input_dim) 입니다. Attention layer와 차원의 의미를 맞춰주기 위해 input을 Transpose하였습니다.
4. Attention Mechanism의 활용
Output이 Sequence 형태라면, input의 특정 부분을 강조해서 보는 형태로 Attention Mechanism을 사용할 수 있습니다. Long-Term dependency를 해결할 때나, 딥러닝 모델의 학습 상황을 점검할 때 활용 가능합니다.
Transformer 및 Transformer를 기반으로 한 모델(BERT, XLNet, GPT 등)은 CNN이나 RNN을 사용하지 않고 Attention만으로 모델이 구현되어 있습니다.
4-1. RNN의 Long-Term Dependency 해결
Long-Term Dependency(장기 의존성)이란 Sequence 길이가 길어지면 앞에 있는 정보와 뒤에 있는 정보의 문맥을 연결하기 어려운 현상을 의미합니다. RNN의 경우 LSTM(Long Short Term Memory Network)나 GRU 등으로 해결했습니다.
Attention Mechanism은 sequence가 길더라도 중요한 벡터에 집중할 수 있으므로, Long-Term Dependency를 해결하는데 사용할 수 있습니다.
4-2. 딥러닝 모델이 잘 학습되었는지 확인할 때

위와 같이 Input 값에 따른 Attention 값을 출력할 수 있습니다. "L'"하고 "The", "1992"하고 "1992" 간의 연관도가 높게 나온 것을 보면, 번역 모델이 잘 학습되었음을 확인할 수 있습니다.
Output에서 Input Sequence 중 어느 값이 중요하게 사용되었는지 알 수 있습니다. 위 이미지 기준 두 단어의 값이 중요하게 사용되었는지 알 수 있습니다. 예를 들어 불어 accord와 영어 agreement는 같은 뜻이므로 Attention Model의 Output이 큰 것을 확인할 수 있다.
참고자료
논문
- Natural Language Inference, Sentence representationand Attention Mechanism
- Attention Is All You Need
기타
'Model > Network' 카테고리의 다른 글
| Autoencoder (0) | 2020.04.12 |
|---|---|
| Transformer (0) | 2020.04.12 |
| GAN(Generative Adversarial Network), 적대적 생성 신경망 (0) | 2020.04.12 |
| Autoencoder / VAE (0) | 2020.04.12 |


