반응형
Fast R-CNN
Submit : Girshick, R. (2015).
Paper : https://arxiv.org/pdf/1504.08083.pdf
Code : https://github.com/rbgirshick/fast-rcnn
1. Method
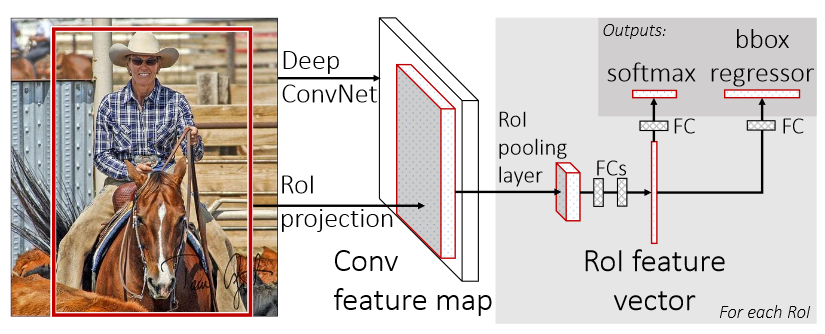
- 한 image에 대하여 Deep Convolution Network(논문에선 VGG의 fc6)를 이용해 feature map을 추출한다.
- Object가 있을 법한 후보군인 region of interest(RoI)를 추출한다.
후보군은 R-CNN과 마찬가지로 selective search를 사용하여 추출. - RoI pooling layer: RoI 영역의 일부라도 포함하고 있는 feature들을 각각 Max Pooling한다.
- RoI feature vector: fully connected layer를 통과시킨 뒤, softmax probability 및 bounding-box regression offset을 추출한다.
즉, RoI가 포함하고 있는 object는 어떤 object인지, 그리고 bounding box의 범위는 어떻게 되는지 알 수 있다.

(1) R-CNN의 문제점
- Train이 multi stage로 진행된다
- ConvNet을 먼저 학습하고, 그 다음에 object detection을 위한 SVM 모델을 학습하고, 그 다음으로 bounding-box regessor를 학습해야 한다.
- Train시 저장 공간과 시간이 많이 필요하다
- feature를 다 추출해서 disk에 저장해 두어야 하므로 저장 공간이 많이 필요
- Feature 추출하는 데만도 시간이 많이 든다
- Object detection 속도 자체도 느리다
(2) Fast R-CNN의 강점
- Convolution feature map은 한 번만 계산해 두면, RoI가 여러 개라도 연산 결과를 재활용할 수 있다.
- Detection quality가 R-CNN, SPPnet보다 높다 (mAP)
- Train이 single stage 진행됨 (classification 부분을 SVM 대신 softmax로 해서 하나의 neural network로 합쳤음)
- Train은 모든 network layer를 update함
- Feature를 미리 계산해서 디스크에 저장해 둘 필요가 없음
(3) RoI pooling layer

- RoI 영역의 feature map을 고정된 크기의 feature map으로 만들어 주는 layer이다.
- RoI는 (r, c, h, w) 튜플로 구성된다. 상단 좌측 corner가 (r, c)이고, height 및 width가 (h, w)이다.
- RoI 영역에 해당하는 feature map을 고정된 크기(H X W, 예: 7 X 7)로 Max Pooling한다.
- h X w 크기의 RoI window를 H x W 크기의 grid로 만들어야 한다. 이 때 h/H X w/W 크기의 filter size를 가지고 Max Pooling하면 된다.
(4) Multi-task loss
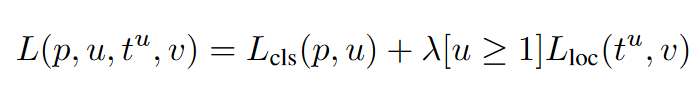
- Fast R-CNN network는하나의 RoI에 대하여 object classification도 해야 하고 bounding box 위치도 찾아야 한다.
- L_cls: 올바른 class로 classification되었는지 나타내는 loss이다.
- cross-entropy loss function과 동일하다.
- K + 1개의 category가 있다. (background인 경우 포함)
- L_loc: 물체의 위치가 올바르게 추출되었는지 나타내는 loss이다.
- u >= 1의 의미: background가 아니다. 즉, background가 아닐 때만 location loss를 사용한다.
- Lambda 값은 1로 고정하고 실험 진행
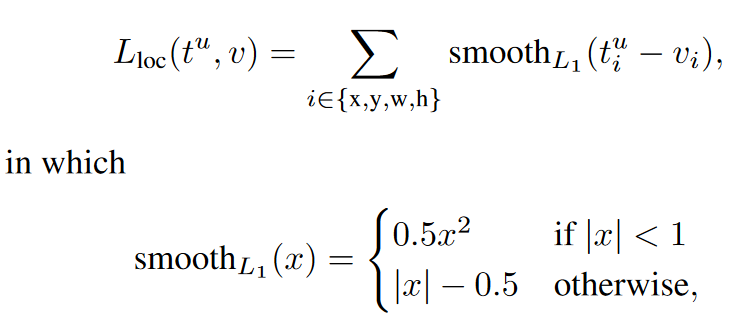
(5) Fast R-CNN detection
- Truncated SVD를 이용해 feature의 차원을 줄여서 fully-connected layer에 넘긴다.
- SVD
- Feature map은 VGG16에서 fc6, fc7 layer를 사용한다. SVD를 이용해 차원을 감소시킨다.
- 25088 X 4096 matrix인 fc6 layer 중 Top 1024 singular value 사용
- 4096 X 4096인 fc7 layer에서 Top 256 singular value 사용
- 이렇게 하면 fully-conencted layer의 연산 시간이 감소한다.
- 성능을 조금만 감소시키면 연산 시간을 상당히 단축시킬 수 있다.
- 전체적인 연산 속도 또한 320ms에서 223ms로 감소하여 30% 정도 줄일 수 있다. 그러나 mAP는 0.3% 정도만 감소.
반응형
'Paper review > Vision' 카테고리의 다른 글
| [논문 리뷰] Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset (0) | 2020.06.14 |
|---|---|
| [논문 리뷰] Adversarial Examples Are Not Bugs, They Are Features (0) | 2020.06.14 |
| [논문 리뷰] A Closer Look at Few shot Classification (0) | 2020.06.14 |
| [논문 리뷰] You Only Look Once: Unified, Real-Time Object Detection (0) | 2020.05.24 |
| [논문 리뷰] R-CNN: Region-based Convolution Network (0) | 2020.05.16 |



